

Ever launched an AI demo that looked perfect in staging, only to watch it fail spectacularly when real users hit it at scale? You're not alone. At Microsoft IC3, I watched brilliant teams build demos that impressed executives but crumbled under production load—costing us months of runway and credibility we couldn't afford to lose.
Most AI education teaches you to chain API calls and fine-tune models. Few teach you how to build systems that survive the chaos of production: network failures, data drift, cost overruns, and users who break your assumptions in creative ways.

The Internal Tooling Wake-Up Call
During Sparkry's early development, I was in classic lean startup mode—moving fast, copy-pasting AI workflows between features, prioritizing demos over durability. My systems worked beautifully until they didn't. One partner integration failed because I hadn't planned for API rate limiting. Another broke when input data shifted slightly from our training distribution.
Then I found The LLM Engineer's Handbook by Paul Iusztin and Maxime Labonne. The book introduced me to something called the "LLM Twin"—personalized AI systems that learn from your existing workflows and adapt over time. But more importantly, it reframed how I thought about production AI entirely.
Adopting their production-first approach boosted my development speed and system intelligence ten-fold within weeks. Not because the AI got smarter, but because the systems got more resilient.
The Mental Model That Changed Everything
Here's the insight that rewired my approach: Production AI isn't about perfect models—it's about graceful failure handling.
Most engineers ask "How do I make my AI smarter?" The LLM Engineer's Handbook taught me to start with "How do I make my AI fail gracefully when facing the unexpected?"
The authors advocate what they call "failure-first architecture": map all your failure modes before you build, then design resilience into your system's foundation rather than bolting it on later. This isn't defensive programming—it's strategic architecture.
At Amazon, we had a name for systems that looked perfect in demos but failed in production: "demo-ware." The gap between demo and production is where most AI projects die, and it's usually not because the model was wrong.
Field-Testing the Framework
I completely restructured Sparkry's AI infrastructure around their production triangle concept. Instead of independent AI workflows that each handled their own failures differently, I built systems that:
Learn from patterns across workflows using the LLM Twin approach
Handle uncertainty with confidence scoring and fallback chains
Scale multiple prompts through a robust shared infrastructure
The transformation was immediate. My BlackLine partner onboarding process went from a fragile demo to a production-ready system. Where I previously had three separate AI workflows (each with their own failure modes), I now had one intelligent system that learned from all interactions and gracefully degraded when components failed.
Development speed increased because I wasn't constantly firefighting production issues. System intelligence improved because the LLM Twin approach meant every workflow made the others smarter.
The Production Mental Model You Can Use
The book centers everything around what they call the "Production Triangle": Resilience, Observability, and Scalability. Every architectural decision gets evaluated against these three axes.
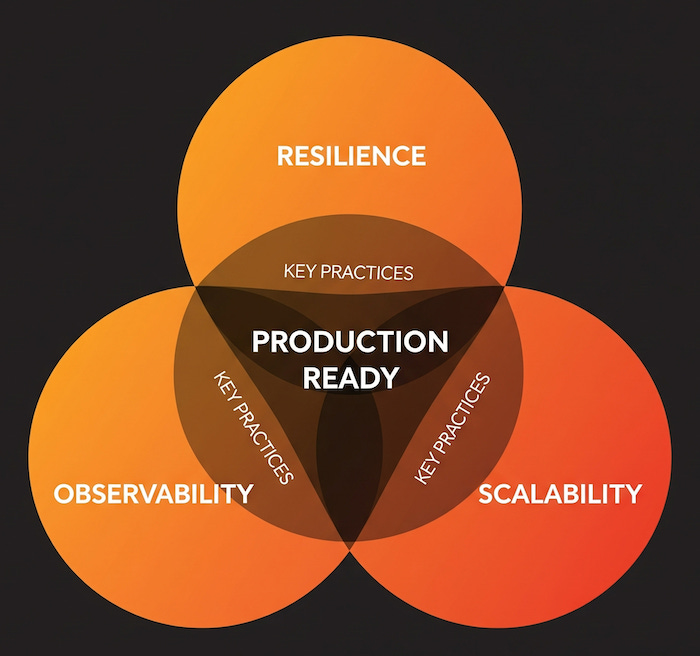
Before deployment:
Map failure modes (slow vector database, faulty LLM responses, network timeouts)
Build observability into your data flows from day one
Test at 10x expected load with noisier, more chaotic data
Design cost controls upfront, not when you get a surprise bill
During production:
Monitor for input drift continuously
Version control your prompts like code
Measure user trust, not just accuracy metrics
Plan for non-breaking model updates
This framework prevents the demo-to-production death gap by making production concerns primary design constraints, not afterthoughts.
Why This Approach Works Now
There's a dangerous gap in the AI education ecosystem. Research papers assume perfect data and infinite compute. Tutorials stop at "hello world" examples. But production systems need to handle real-world chaos while staying profitable.
The LLM Engineer's Handbook bridges this gap. The authors bring battle-tested expertise from building GenAI systems at scale. They've paid the tuition in downtime, debugging, and surprise AWS bills.
The field is flooded with people who can call Claude APIs, but starved for production-focused architects who understand operational trade-offs. This book teaches the operational thinking that creates lasting competitive advantage.
Your Production Reality Check
What's your biggest failure mode when moving from prototype to production?
Cost overruns?
Latency spikes?
Data drift detection?
If you're building production RAG systems, what breaks first when you scale?
The vector database?
The embedding pipeline?
The LLM inference costs?
Drop your war stories below. The best learning comes from engineers who've been on-call at 3 AM, watching their "perfect" demo system melt down under real load.
For my full curated list of AI and Tech leadership books, check out the Sparkry.AI Reading List.
What book completely changed how you think about production systems? Share the title that saved you from a major outage or cost disaster—I'm building a library of must-reads for anyone who's ever been paged at 3 AM.